// g++ test.cpp -o test.out -std=c++11 #include<bits/stdc++.h> usingnamespace std; typedeflonglong ll; #define rep(i, a, b) for(int i = int(a); i <= int(b); ++i) #define per(i, b, a) for(int i = int(b); i >= int(a); --i) #define mem(x, y) memset(x, y, sizeof(x)) #define SZ(x) x.size() #define mk make_pair #define pb push_back #define fi first #define se second const ll mod=1000000007; constint inf = 0x3f3f3f3f; inlineintrd(){char c=getchar();int x=0,f=1;while(c<'0'||c>'9'){if(c=='-')f=-1;c=getchar();}while(c>='0'&&c<='9'){x=x*10+c-'0';c=getchar();}return x*f;} inline ll qpow(ll a,ll b){ll ans=1%mod;for(;b;b>>=1){if(b&1)ans=ans*a%mod;a=a*a%mod;}return ans;}
classSolution { public: vector<string> findWords(vector<string>& words){ int word_to_line[128]; string str[] = {"qwertyuiopQWERTYUIOP", "asdfghjklASDFGHJKL", "zxcvbnmZXCVBNM"}; vector<string> lines(str, str+3); int sz = lines.size(); for (int i = 0; i < sz; i++) { for (char x : lines[i]) { word_to_line[x] = i; } } // for (int i = 0; i < 128; i++) { // printf("%c %d\n", i, word_to_line[i]); // }
vector<string> ans; int param_word_sz; bool flag; for (auto word : words) { param_word_sz = word.size(); flag = 1; // puts(word.c_str()); for (int i = 0; i < param_word_sz - 1; i++) { if (word_to_line[word[i]] != word_to_line[word[i + 1]]) { // 尴尬,没有处理大小写,导致多调试了15分钟 // printf("word not in one line %c, %c\n", // word[i], word[i + 1]); flag = 0; break; } } if (flag) { ans.push_back(word); } }
return ans; } };
intmain(){ Solution sol; string words_str[] = {"Hello","Alaska","Dad","Peace"}; vector<string> words(words_str, words_str + 4); vector<string> ans; ans = sol.findWords(words); for (auto x : ans) { puts(x.c_str()); }
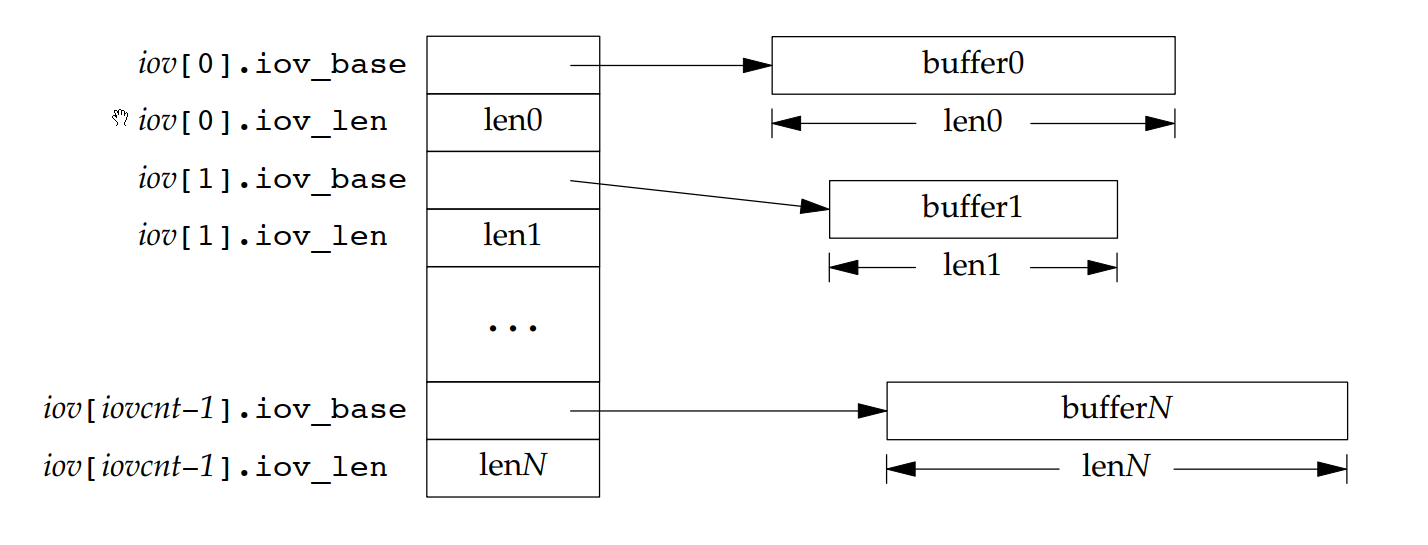
intmain(){ structioveciov[4]; ssize_t nr; int fd, i;
char *buf[] = {"The term buccaneer comes from the word boucan.\n", "A boucan is a wooden frame used for cooking meat.\n", "Buccaneer is the West Indies name for a pirate.\n"};